总览:

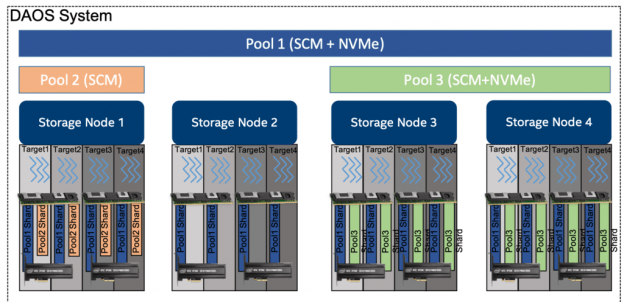
一个POOL是指预分配的一些存储空间,这些存储空间会分布在多个target上,具体分配到每一个target的容量大小叫做pool分区(pool shard)。POOL的大小是在创建时期制定好的,它可以通过调整每个pool shard的大小来扩缩容,也可以添加更多的target到pool中进行扩容(添加更多的storage node)。 POOL在DAOS中提供了对的存储虚拟化,同时也是存储隔离和资源分配的单元。
一个pool可以包含有多个具有事务特性的对象存储,叫做容器(container)。每个容器都是一个私有的对象地址空间(private object address space),相对于存储在同一个pool中的其他容器相互隔离,同时可以做事务性的任务。容器是DAOS中快照和数据管理的单元。DAOS对象(DAOS objects)存储在容器中,可以被分布在当前pool的任意的target上,这样就提高了性能和恢复能力。DAOS对象可以通过多种API方式访问,可以抽象表示结构化,半结构化和非结构化的数据。

系统结构:
POOL:
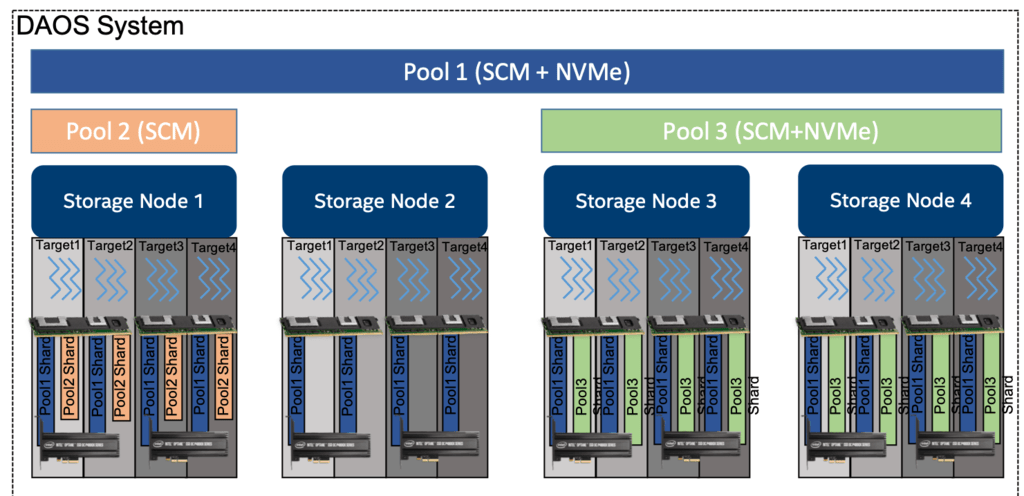
每个pool都有自己唯一的uuid(pool uuid),同时维护着一个持久化的,具有版本控制的表pool map,表中存储着这个pool的target成员信息。target成员是确定和一致的(definitive and consistent),每次成员的变更,都会按照顺序记录(sequentially numbered)。pool map中不仅有在线的target的列表(list of active targets),还包含着存储的拓扑结构(storage topology),以一颗树的形式存储,用来标识共享相同硬件的target。例如,树的第一级可以表示共享同一块主板的所有target,树的第二级可以表示共享同一个机架(rack)中的所有主板,那么树的第三级可以表示共享同一个cage的所有rack。
按照这个框架,有效的按照层次表示出了错误域(hierarchical fault domains),这样就可以避免把冗余的数据放在可能同时挂掉的target上。在任意时间,都可以把新的target添加到pool map中,也可以把挂掉的target移出pool map,并且,由于pool map是具有版本的(fully versioned),所以每次对pool map的修改都会分配一个唯一的序列,尤其是当移出target的时候。
pool shard是在持久化内存中的预留,它也可以通过在特定target的NVME盘上预分配一片空间,结合持久化内存(persistent memory)一起来使用。pool shard大小固定,当容量已满的时候,所有的操作会失败。它的当前用量可以随时查询,同时可以知道每种数据类型在pool shard中所占用的空间。
当target挂掉并且从pool map中移出的时候,pool中的冗余数据会被自动恢复上线。这个恢复过程叫做rebuild。rebuild过程会被记录在持久化内存的特殊日志里,来表示连锁错误(cascading failures)。当新的target添加到pool map后,数据会自动迁移到新的节点,以确保数据是平均分布在所有的target成员上的。添加新target的过程叫做空间重平衡(space rebalancing),这个过程同样使用一个独立的持久化日志,来防止中断或者系统重启。一个pool就是一组分布在不同存储节点(storage node)的target成员,数据和元数据随着target成员也分布在了不同的存储节点上,这样就获得了较好的横向扩展,多副本和纠删码能力,同时保证了数据的持久性和高可用(achieve horizontal scalability, and replicated or erasure-coded to ensure durability and availability)。
当创建一个pool的时候,我们需要指定一些系统属性,同时用户也可以定义自己的属性,也会被持久化存储。pool仅允许授权或认证过的应用连接(authenticated and authorized applications),可以使用多种安全框架加来做认证,pool是强制开启安全认证的。连接成功后,连接上下文会被返回到用户进程中(a connection context is returned to the application process)。
pool存储着多种类型的元数据,包括pool map,认证信息,用户属性,系统属性和重建日志(pool map, authentication and authorization information, user attributes, properties, and rebuild logs)。这些元数据都需要高级别的弹性能力(resiliency),因此,pool的元数据有多个副本,分别存储在了不同的错误域(distinct high-level fault domains)中。对于大量存储节点来说,只有一小部分运行pool元数据服务(pool metadata service),在有限个存储节点的情况下,DAOS可以使用一致性算法(consensus algorithm)来保证数据在有错误的情况下的一致性(consistency in the presence of faults),从而避免脑裂问题(split-brain syndrome)。
当访问一个pool的时候,用户进程需要连接并且通过pool的安全认证,之后这个连接可以通过local2global()和global2local()共享给用户的相关进程。这样可以避免分布式任务同时获取元数据而导致的问题。当申请这个连接的进程断开连接时,那么这个连接就会被pool收回。
Container:
container表示pool中的一个对象地址空间(object address space),同样通过UUID来做标识。下图为container的类型以及用户的使用方式:

和pool一样,在创建容器的时候需要设置一些属性,来启用容器的不同功能,例如checksum。
当访问一个容器的时候,用户应用必须首先连接到当前容器所在的池,然后打开这个容器。如果当前应用拥有访问这个容器的权限,那么就会返回一个容器句柄(container handle)。返回的容器句柄拥有授权用户应用内的任意进程访问当前容器和内容的能力,同样,打开当前容器的进程同样可以共享获得的容器句柄给属于它的进程,当容器关闭时,权限会被收回。
容器内的不同对象可以在target上拥有不同的数据模式和冗余类型。想要定义对象的数据模式,那么必须需要一些参数,比如动态或静态条,复制或纠删码(Dynamic or static striping, replication, or erasure code)。对象类(object class)预先为一组对象定义了公共的数据模式属性,每一个对象类都被分配了一个唯一的id,同时这个对象会和pool级别的模式相关联(associated with a given schema at the pool level)。
新的对象类可以通过模式配置(configurable schema)随时定义,但是定义好后就不可变(当这个模式的所有对象都被销毁后,可以修改)。下表是DAOS POOL预先定义好的对象类:
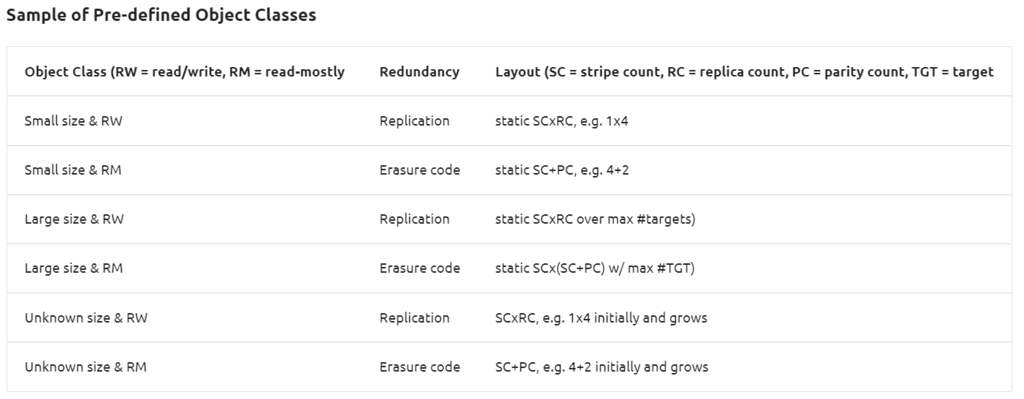
如下面的表格所示,每一个容器中的对象都是通过一个128位的对象地址(128-bit object address)来标识。高32位(high 32 bits)预留给了DAOS,用来存储一些内部元数据,例如对象类(object class)。剩余的96位是被用户所管理,同时剩余的96位在同一个容器中是唯一的,它可以被用来存储上层的元数据(used by upper layers of the stack to encode their metadata),DAOS API 提供了一个可伸缩的64位对象id分配器。被存储下来的对象id是完整的128位地址,而且仅供一次性使用,只与一种对象模式相关联(only a single object schema)。
object id structure
<———————————- 128 bits ———————————->
——————————————————————————–
|DAOS Internal Bits| Unique User Bits |
——————————————————————————–
<—- 32 bits —-><————————- 96 bits ————————->
容器是事务和版本控制的基本单元,所有对容器中对象的操作都会被DAOS库添加时间戳,这个时间戳叫做epoch。DAOS transaction API允许合并多个操作为一个原子操作,然后通过epoch ordering提供多版本并发控制(multi-version concurrency control)。所有被记录下来的版本更新,都可以定期聚合(aggregated),回收被重叠写入(overlapping writes)所占用的空间,同时降低元数据的复杂度。快照是放置在特定epoch上的永久引用,同时避免被聚合回收。
容器的元数据(list of snapshots, container open handles, object class, user attributes, properties, and others)存储在持久化内存里,通过一个独立的container metadata service服务维护,这个服务可以使用parent metadata pool service或者自己专用的复制引擎(maintained by a dedicated container metadata service that either uses the same replicated engine as the parent metadata pool service, or has its own engine)。在创建容器的时候可以指定这个配置。
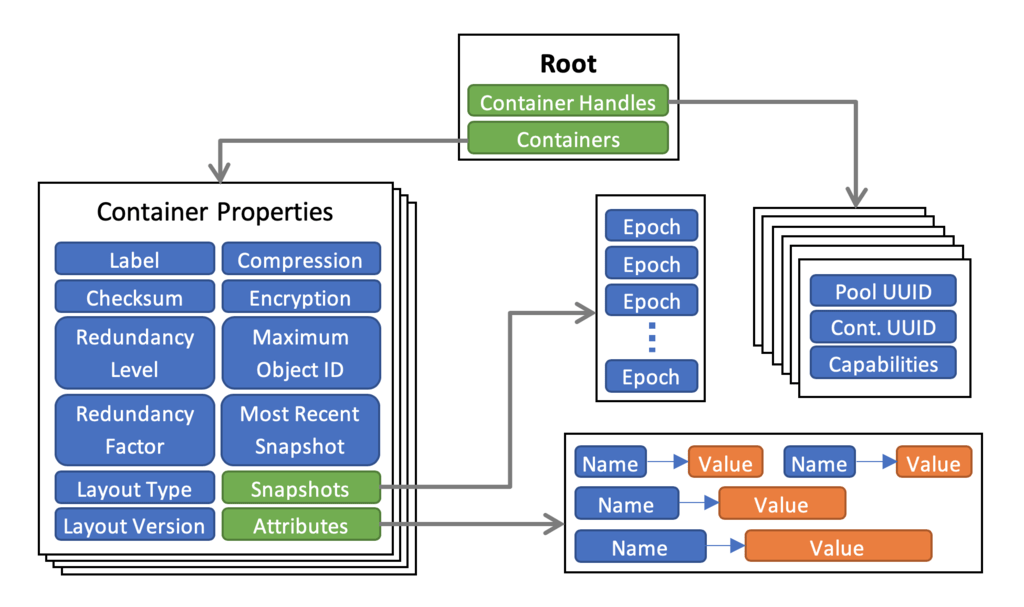
访问方式和pool一样,前文已说过:
Like a pool, access to a container is controlled by the container handle. To acquire a valid handle, an application process must open the container and pass the security checks. This container handle may then be shared with other peer application processes via the container local2global() and global2local() operations.
Object:
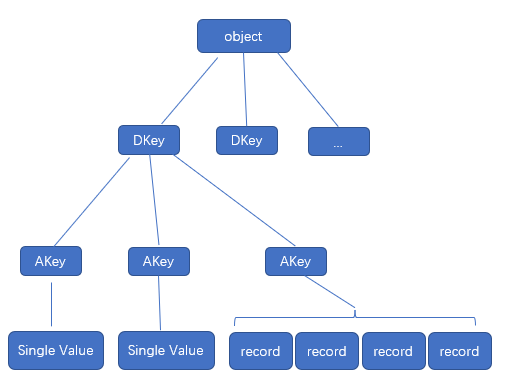
To avoid scaling problems and overhead common to a traditional storage system, DAOS objects are intentionally simple. No default object metadata beyond the type and schema is provided. This means that the system does not maintain time, size, owner, permissions or even track openers. To achieve high availability and horizontal scalability, many object schemas (replication/erasure code, static/dynamic striping, and others) are provided. The schema framework is flexible and easily expandable to allow for new custom schema types in the future. The layout is generated algorithmically on object open from the object identifier and the pool map. End-to-end integrity is assured by protecting object data with checksums during network transfer and storage.
A DAOS object can be accessed through different APIs:
Multi-level key-array API is the native object interface with locality feature. The key is split into a distribution (dkey) and an attribute (akey) key. Both the dkey and akey can be of variable length and type (a string, an integer or even a complex data structure). All entries under the same dkey are guaranteed to be collocated on the same target. The value associated with akey can be either a single variable-length value that cannot be partially overwritten, or an array of fixed-length values. Both the akeys and dkeys support enumeration.
Key-value API provides a simple key and variable-length value interface. It supports the traditional put, get, remove and list operations.
Array API implements a one-dimensional array of fixed-size elements addressed by a 64-bit offset. A DAOS array supports arbitrary extent read, write and punch operations.
参考:https://docs.daos.io/v2.0/overview/storage/#storage-model
发表回复