认真的ricky
@
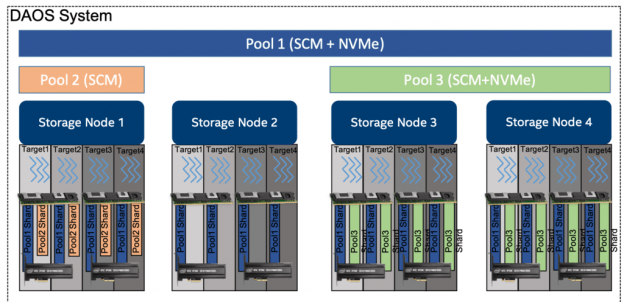
总览: 一个POOL是指预分配的一些存储空间,这些存储空间会分布在多个target上,具体分配到每一个targ…
go中的函数闭包(Function Closures)对于我来说比较难理解, 在之前的开发中也没有用到其他语言…
在学习结构体指针的时候有些疑问, 首先定义一个结构体, 初始化结构体和它的结构体指针:
迭代泛型 泛型使用处理一些实体(比如 List)的特殊语法增强了 Java 语言,您通常可能希望逐个元素地处理…
非常非常棒的JAVA教程,来自于IBM https://www.ibm.com/developerworks/…
IO流的继承关系图 字节流(Byte Streams) 字节流处理原始的二进制数据 I/O。输入输出的是8位字…
Features It is thread-safe. It is optimized for speed. …
基本类型的封装类 所有的基本类型,都有对应的类类型,比如int对应的类是Integer,这种类就叫做封装类. …
概述 在Java中,所有的事件都能由类描述,Java中的异常就是由java.lang包下的异常类描述的。 1、…
位运算 java支持的位运算符: 位运算符中,除~以外,其余均为二元运算符.操作数只能为整型和字符型数据.Ja…