IO流的继承关系图
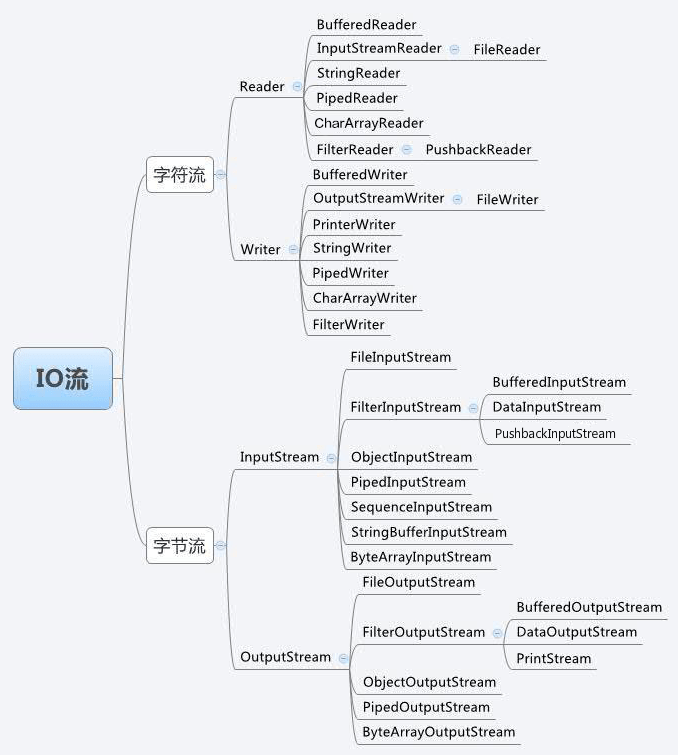
字节流(Byte Streams)
字节流处理原始的二进制数据 I/O。输入输出的是8位字节,相关的类为 InputStream 和 OutputStream.
字节流的类有许多。为了演示字节流的工作,我们将重点放在文件 I/O 字节流 FileInputStream 和 FileOutputStream 上。其他种类的字节流用法类似,主要区别在于它们构造的方式,大家可以举一反三。
用法
下面一例子 CopyBytes, 从 xanadu.txt 文件复制到 outagain.txt,每次只复制一个字节:
public class CopyBytes {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
FileInputStream in = null;
FileOutputStream out = null;
try {
in = new FileInputStream("resources/xanadu.txt");
out = new FileOutputStream("resources/outagain.txt");
int c;
while ((c = in.read()) != -1) {
out.write(c);
}
} finally {
if (in != null) {
in.close();
}
if (out != null) {
out.close();
}
}
}
}
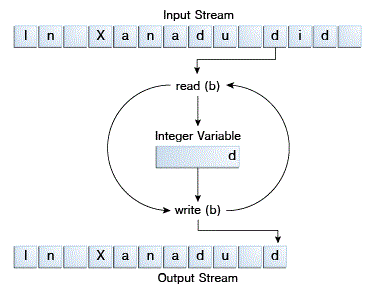
CopyBytes 花费其大部分时间在简单的循环里面,从输入流每次读取一个字节到输出流,如图所示:
记得始终关闭流
不再需要一个流记得要关闭它,这点很重要。所以,CopyBytes 使用 finally 块来保证即使发生错误两个流还是能被关闭。这种做法有助于避免严重的资源泄漏。
一个可能的错误是,CopyBytes 无法打开一个或两个文件。当发生这种情况,对应解决方案是判断该文件的流是否是其初始 null 值。这就是为什么 CopyBytes 可以确保每个流变量在调用前都包含了一个对象的引用。
何时不使用字节流
CopyBytes 似乎是一个正常的程序,但它实际上代表了一种低级别的 I/O,你应该避免。因为 xanadu.txt 包含字符数据时,最好的方法是使用字符流,下文会有讨论。字节流应只用于最原始的 I/O。所有其他流类型是建立在字节流之上的。
字符流(Character Streams)
字符流处理字符数据的 I/O,自动处理与本地字符集转化。
Java 平台存储字符值使用 Unicode 约定。字符流 I/O 会自动将这个内部格式与本地字符集进行转换。在西方的语言环境中,本地字符集通常是 ASCII 的8位超集。
对于大多数应用,字符流的 I/O 不会比 字节流 I/O操作复杂。输入和输出流的类与本地字符集进行自动转换。使用字符的程序来代替字节流可以自动适应本地字符集,并可以准备国际化,而这完全不需要程序员额外的工作。
如果国际化不是一个优先事项,你可以简单地使用字符流类,而不必太注意字符集问题。以后,如果国际化成为当务之急,你的程序可以方便适应这种需求的扩展。见国际化获取更多信息。
Java采用 Unicode 字符集,每个字符和汉字都采用2个字节进行编码,ASCII 码是 Unicode 编码的自集
InputStreamReader 是 字节流 到 字符桥的桥梁 ( byte->char 读取字节然后用特定字符集编码成字符)
OutputStreamWriter是 字符流 到 字节流的桥梁 ( char->byte )
他们是在字节流的基础上加了桥梁作用,所以构造他们时要先构造普通文件流
我们常用的是:
BufferedReader 方法:readLine()
PrintWriter 方法:println()
用法
字符流类描述在 Reader 和 Writer。而对应文件 I/O ,在 FileReader 和 FileWriter,下面是一个 CopyCharacters 例子:
public class CopyCharacters {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
FileReader inputStream = null;
FileWriter outputStream = null;
try {
inputStream = new FileReader("resources/xanadu.txt");
outputStream = new FileWriter("resources/characteroutput.txt");
int c;
while ((c = inputStream.read()) != -1) {
outputStream.write(c);
}
} finally {
if (inputStream != null) {
inputStream.close();
}
if (outputStream != null) {
outputStream.close();
}
}
}
}
CopyCharacters 与 CopyBytes 是非常相似的。最重要的区别在于 CopyCharacters 使用的 FileReader 和 FileWriter 用于输入输出,而 CopyBytes 使用 FileInputStream 和FileOutputStream 中的。请注意,这两个CopyBytes和CopyCharacters使用int变量来读取和写入;在 CopyCharacters,int 变量保存在其最后的16位字符值;在 CopyBytes,int 变量保存在其最后的8位字节的值。
字符使用字节流
字符流往往是对字节流的“包装”。字符流使用字节流来执行物理I/O,同时字符流处理字符和字节之间的转换。例如,FileReader 使用 FileInputStream,而 FileWriter使用的是 FileOutputStream。
面向行的I/O操作
字符 I/O 通常发生在较大的单位不是单个字符。一个常用的单位是行:用行结束符结尾。行结束符可以是回车/换行序列(“\r\n”),一个回车(“\r”),或一个换行符(“\n”)。支持所有可能的行结束符,程序可以读取任何广泛使用的操作系统创建的文本文件。
修改 CopyCharacters 来演示如使用面向行的 I/O。要做到这一点,我们必须使用两个类,BufferedReader 和 PrintWriter 的。
该 CopyLines 示例调用 BufferedReader.readLine 和 PrintWriter.println 同时做一行的输入和输出。
public class CopyLines {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
BufferedReader inputStream = null;
PrintWriter outputStream = null;
try {
inputStream = new BufferedReader(new FileReader("resources/xanadu.txt"));
outputStream = new PrintWriter(new FileWriter("resources/characteroutput.txt"));
String l;
while ((l = inputStream.readLine()) != null) {
outputStream.println(l);
}
} finally {
if (inputStream != null) {
inputStream.close();
}
if (outputStream != null) {
outputStream.close();
}
}
}
}
调用 readLine 按行返回文本行。CopyLines 使用 println 输出带有当前操作系统的行终止符的每一行。这可能与输入文件中不是使用相同的行终止符。
缓冲流(Buffered Streams)
缓冲流通过减少调用本地 API 的次数来优化的输入和输出。
目前为止,大多数时候我们到看到使用非缓冲 I/O 的例子。这意味着每次读或写请求是由基础 OS 直接处理。这可以使一个程序效率低得多,因为每个这样的请求通常引发磁盘访问,网络活动,或一些其它的操作,而这些是相对昂贵的。
为了减少这种开销,所以 Java 平台实现缓冲 I/O 流。缓冲输入流从被称为缓冲区(buffer)的存储器区域读出数据;仅当缓冲区是空时,本地输入 API 才被调用。同样,缓冲输出流,将数据写入到缓存区,只有当缓冲区已满才调用本机输出 API。
程序可以转换的非缓冲流为缓冲流,这里用非缓冲流对象传递给缓冲流类的构造器。
inputStream = new BufferedReader(new FileReader("xanadu.txt"));
outputStream = new BufferedWriter(new FileWriter("characteroutput.txt"));
用于包装非缓存流的缓冲流类有4个:BufferedInputStream 和 BufferedOutputStream 用于创建字节缓冲字节流, BufferedReader 和 BufferedWriter 用于创建字符缓冲字节流。
刷新缓冲流
刷新缓冲区是指在某个缓冲的关键点就可以将缓冲输出,而不必等待它填满。
一些缓冲输出类通过一个可选的构造函数参数支持 autoflush(自动刷新)。当自动刷新开启,某些关键事件会导致缓冲区被刷新。例如,自动刷新 PrintWriter 对象在每次调用 println 或者 format 时刷新缓冲区。查看 Formatting 了解更多关于这些的方法。
如果要手动刷新流,请调用其 flush 方法。flush 方法可以用于任何输出流,但对非缓冲流是没有效果的。
扫描(Scanning)和格式化(Formatting)
扫描
将其输入分解为标记
默认情况下,Scanner 使用空格字符分隔标记。(空格字符包括空格,制表符和行终止符。为完整列表,请参阅 Character.isWhitespace)。示例 ScanXan 读取 xanadu.txt 的单个词语并打印他们:
public class ScanXan {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
Scanner s = null;
try {
s = new Scanner(new BufferedReader(new FileReader("resources/xanadu.txt")));
while (s.hasNext()) {
System.out.println(s.next());
}
} finally {
if (s != null) {
s.close();
}
}
}
}
虽然 Scanner 不是流,但你仍然需要关闭它,以表明你与它的底层流执行完成。
调用 useDelimiter() ,指定一个正则表达式可以使用不同的标记分隔符。例如,假设您想要标记分隔符是一个逗号,后面可以跟空格。你会调用s.useDelimiter(",\\s*");
转换成独立标记
该 ScanXan 示例是将所有的输入标记为简单的字符串值。Scanner 还支持所有的 Java 语言的基本类型(除 char),以及 BigInteger 和 BigDecimal 的。此外,数字值可以使用千位分隔符。因此,在一个美国的区域设置,Scanner 能正确地读出字符串“32,767”作为一个整数值。
这里要注意的是语言环境,因为千位分隔符和小数点符号是特定于语言环境。所以,下面的例子将无法正常在所有的语言环境中,如果我们没有指定 scanner 应该用在美国地区工作。可能你平时并不用关心,因为你输入的数据通常来自使用相同的语言环境。可以使用下面的语句来设置语言环境:s.useLocale(Locale.US);
该 ScanSum 示例是将读取的 double 值列表进行相加:
public class ScanSum {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
Scanner s = null;
double sum = 0;
try {
s = new Scanner(new BufferedReader(new FileReader("resources/usnumbers.txt")));
s.useLocale(Locale.US);
while (s.hasNext()) {
if (s.hasNextDouble()) {
sum += s.nextDouble();
} else {
s.next();
}
}
} finally {
s.close();
}
System.out.println(sum);
}
}
输出为:1032778.74159
格式化
实现格式化流对象要么是 字符流类的 PrintWriter 的实例,或为字节流类的 PrintStream 的实例。
注:对于 PrintStream 对象,你很可能只需要 System.out 和 System.err。 (请参阅命令行I/O)当你需要创建一个格式化的输出流,请实例化 PrintWriter,而不是 PrintStream。
像所有的字节和字符流对象一样,PrintStream 和 PrintWriter 的实例实现了一套标准的 write 方法用于简单的字节和字符输出。此外,PrintStream 和 PrintWriter 的执行同一套方法,将内部数据转换成格式化输出。提供了两个级别的格式:
- print 和 println 在一个标准的方式里面格式化独立的值 。
- format 用于格式化几乎任何数量的格式字符串值,且具有多种精确选择。
print 和 println 方法*
调用 print 或 println 输出使用适当 toString 方法变换后的值的单一值。我们可以看到这 Root 例子:
public class Root {
/**
* @param args
*/
public static void main(String[] args) {
int i = 2;
double r = Math.sqrt(i);
System.out.print("The square root of ");
System.out.print(i);
System.out.print(" is ");
System.out.print(r);
System.out.println(".");
i = 5;
r = Math.sqrt(i);
System.out.println("The square root of " + i + " is " + r + ".");
}
}
输出为:
The square root of 2 is 1.4142135623730951.
The square root of 5 is 2.23606797749979.
format 方法
该 format 方法用于格式化基于 format string(格式字符串) 多参。格式字符串包含嵌入了 format specifiers (格式说明)的静态文本;除非使用了格式说明,否则格式字符串输出不变。
格式字符串支持许多功能。在本教程中,我们只介绍一些基础知识。有关完整说明,请参阅 API 规范关于格式字符串语法。
Root2 示例在一个 format 调用里面设置两个值:
public class Root2 {
/**
* @param args
*/
public static void main(String[] args) {
int i = 2;
double r = Math.sqrt(i);
System.out.format("The square root of %d is %f.%n", i, r);
}
}
输出为:The square root of 2 is 1.414214.
像本例中所使用的格式为:
- d 格式化整数值为小数
- f 格式化浮点值作为小数
- n 输出特定于平台的行终止符。
这里有一些其他的转换格式:
- x 格式化整数为十六进制值
- s 格式化任何值作为字符串
- tB 格式化整数作为一个语言环境特定的月份名称。
还有许多其他的转换。
注意:除了 %% 和 %n,其他格式符都要匹配参数,否则抛出异常。在 Java 编程语言中,\ n转义总是产生换行符(\u000A)。不要使用\ñ除非你特别想要一个换行符。为了针对本地平台得到正确的行分隔符,请使用%n。
除了用于转换,格式说明符可以包含若干附加的元素,进一步定制格式化输出。下面是一个 Format 例子,使用一切可能的一种元素。
public class Format {
/**
* @param args
*/
public static void main(String[] args) {
System.out.format("%f, %1$+020.10f %n", Math.PI);
}
}
输出为:3.141593, +00000003.1415926536
附加元素都是可选的。下图显示了长格式符是如何分解成元素
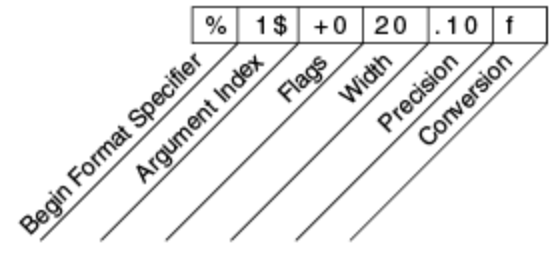
元件必须出现在显示的顺序。从合适的工作,可选的元素是:(摘抄博主原文,可能是用翻译直接翻过来的,不通顺)
- Precision(精确)。对于浮点值,这是格式化值的数学精度。对于 s 和其他一般的转换,这是格式化值的最大宽度;该值右截断,如果有必要的。
- Width(宽度)。格式化值的最小宽度;如有必要,该值被填充。默认值是左用空格填充。
- Flags(标志)指定附加格式设置选项。在 Format 示例中,+ 标志指定的数量应始终标志格式,以及0标志指定0是填充字符。其他的标志包括 – (垫右侧)和(与区域特定的千位分隔符格式号)。请注意,某些标志不能与某些其他标志或与某些转换使用。
上面的格式和C语言printf的使用方法是相类似的,不必过于细看
4. Argument Index(参数索引)允许您指定的参数明确匹配。您还可以指定<到相同的参数作为前面的说明一致。这样的例子可以说:System.out.format(“%F,%<+ 020.10f%N”,Math.PI);
Argument Index:可以理解为自由匹配参数,不用按照”,”后面所写的顺序了.例如:
import java.util.Formatter;
// j a va 2 s. c om
public class Main {
public static void main(String args[]) {
Formatter fmt = new Formatter();
fmt.format("%3$d %1$d %2$d", 10, 20, 30);
System.out.println(fmt);
}
}
输出:
30 10 20%3$d表示用后面的第三个参数(30),匹配%d的格式来输出,同理,1$就是表示匹配第一个参数了,所以
最后的输出结果不是按照所传入的顺序,而是按照$所指定的顺序.
命令行 I/O
命令行 I/O 描述了标准流(Standard Streams)和控制台(Console)对象。
Java 支持两种交互方式:标准流(Standard Streams)和通过控制台(Console)。
标准流
标准流是许多操作系统的一项功能。默认情况下,他们从键盘读取输入和写出到显示器。它们还支持对文件和程序之间的 I/O,但该功能是通过命令行解释器,而不是由程序控制。
Java平台支持三种标准流:标准输入(Standard Input, 通过 System.in 访问)、标准输出(Standard Output, 通过System.out 的访问)和标准错误( Standard Error, 通过System.err的访问)。这些对象被自动定义,并不需要被打开。标准输出和标准错误都用于输出;错误输出允许用户转移经常性的输出到一个文件中,仍然能够读取错误消息。
您可能希望标准流是字符流,但是,由于历史的原因,他们是字节流。 System.out 和System.err 定义为 PrintStream 的对象。虽然这在技术上是一个字节流,PrintStream 利用内部字符流对象来模拟多种字符流的功能。
相比之下,System.in 是一个没有字符流功能的字节流。若要想将标准的输入作为字符流,可以包装 System.in 在 InputStreamReader
InputStreamReader cin = new InputStreamReader(System.in);
Console (控制台)
更先进的替代标准流的是 Console 。这个单一,预定义的 Console 类型的对象,有大部分的标准流提供的功能,另外还有其他功能。Console 对于安全的密码输入特别有用。Console 对象还提供了真正的输入输出字符流,是通过 reader 和 writer 方法实现的。
若程序想使用 Console ,它必须尝试通过调用 System.console() 检索 Console 对象。如果 Console 对象存在,通过此方法将其返回。如果返回 NULL,则 Console 操作是不允许的,要么是因为操作系统不支持他们或者是因为程序本身是在非交互环境中启动的。
Console 对象支持通过读取密码的方法安全输入密码。该方法有助于在两个方面的安全。第一,它抑制回应,因此密码在用户的屏幕是不可见的。第二,readPassword 返回一个字符数组,而不是字符串,所以,密码可以被覆盖,只要它是不再需要就可以从存储器中删除。
Password 例子是一个展示了更改用户的密码原型程序。它演示了几种 Console 方法
public class Password {
/**
* @param args
*/
public static void main(String[] args) {
Console c = System.console();
if (c == null) {
System.err.println("No console.");
System.exit(1);
}
String login = c.readLine("Enter your login: ");
char [] oldPassword = c.readPassword("Enter your old password: ");
if (verify(login, oldPassword)) {
boolean noMatch;
do {
char [] newPassword1 = c.readPassword("Enter your new password: ");
char [] newPassword2 = c.readPassword("Enter new password again: ");
noMatch = ! Arrays.equals(newPassword1, newPassword2);
if (noMatch) {
c.format("Passwords don't match. Try again.%n");
} else {
change(login, newPassword1);
c.format("Password for %s changed.%n", login);
}
Arrays.fill(newPassword1, ' ');
Arrays.fill(newPassword2, ' ');
} while (noMatch);
}
Arrays.fill(oldPassword, ' ');
}
// Dummy change method.
static boolean verify(String login, char[] password) {
// This method always returns
// true in this example.
// Modify this method to verify
// password according to your rules.
return true;
}
// Dummy change method.
static void change(String login, char[] password) {
// Modify this method to change
// password according to your rules.
}
}
上面的流程是:
- 尝试检索 Console 对象。如果对象是不可用,中止。
- 调用 Console.readLine 提示并读取用户的登录名。
- 调用 Console.readPassword 提示并读取用户的现有密码。
- 调用 verify 确认该用户被授权可以改变密码。(在本例中,假设 verify 是总是返回true )
- 重复下列步骤,直到用户输入的密码相同两次:
调用 Console.readPassword 两次提示和读一个新的密码。 如果用户输入的密码两次,调用 change 去改变它。 (同样,change 是一个虚拟的方法) 用空格覆盖这两个密码。 - 用空格覆盖旧的密码。
数据流(Data Streams), 对象流(Object Streams)由于篇幅原因,请参考
原文链接
Java 编程要点| 非常棒的开源java书籍
gitbooks链接
Log4j基本用法
篇幅原因,请点这里
参考
Java 编程要点之 I/O 流详解
Java I/O 操作及优化详细介绍
《JAVA I/O最详解》
Formatter Argument Index
Java String Format Examples
发表回复